Năm 2023, tôi lần đầu mention ChatGPT trong khoá SSS đợt 17. Năm 2024, tôi tự xây 8 LonGPT. Năm 2026 này — tôi có 22 LonGPT, vault Obsidian + Claude Code làm “bộ não thứ 2”, và không thể tưởng tượng nổi cảnh mình quay lại làm việc không có AI.
Tôi là Phạm Thành Long. Category này không phải về “AI tools cool”. Nó về cách doanh nhân Việt dùng AI để TIẾT KIỆM 80% thời gian + 80% công sức trong content, marketing, sales, quản trị.
Bạn sẽ tìm thấy:
22 LonGPT catalog — bộ custom GPT tôi tự build cho IPS (9 GPT) / LTVM (3 GPT) / Eagle Camp (7 GPT) / Khác (3 GPT) Bộ não thứ 2 — Obsidian + Claude theo Andrej Karpathy, lưu mọi kiến thức 1 lần dùng cả đời ChatGPT cho kinh doanh — khoá entry-level + prompt cơ bản AI cho Marketing — AI Teaser EC21.4 (16 module bài quảng cáo, 16⁴ = 65.536 phiên bản từ 1 chủ đề) AI cho Sales — Hot Seat AI Brainstorm, Bạch Cốt Tinh adversarial test AI vs Con người — 9 đặc tính khác biệt (Karpathy), 5 cái chết tư duy do dùng AI sai 10 thiên kiến nhận thức — counter-debate với AI để ra quyết định tốt hơn Công cụ thực chiến — Claude Code 1 tuần, n8n automation, backup vault Obsidian
Đây là category trẻ nhất trên long.vn — và đang là sóng SEO mạnh nhất 2026.
Pillar: “Bộ não thứ 2 cho doanh nhân — Obsidian + AI Workflow”.
Phạm Thành Long ghi lại 1 tuần làm việc nghiêm túc với Claude Code: 13 bài học về AI workflow, 9 đặc tính AI con người thiếu, 5 cái chết tư duy doanh nhân, kiến trúc Bộ não thứ 2 multi-agent.
Tác giả: Phạm Thành Long · Cập nhật: 05/05/2026
5 ý chính cần biết: Tôi không gặp học viên suốt 1 tuần. Tôi ngồi một mình với Claude Code của Anthropic, ghi âm, hỏi, phân tích — và rút ra 13 bài học khiến tôi phải viết lại 13 năm giáo án. AI có 6 đặc tính mà 99% nhân viên không có: làm việc đến cùng, học liên tục, mở rộng khả năng, giải quyết việc khó, phối hợp đội nhóm, báo cáo tiến độ không giấu diếm. Con người bị kìm hãm âm thầm bởi 5 cái chết tư duy: giấu dốt, tưởng mình giỏi, không phối hợp, chờ hoàn hảo, thiếu hồi phục. Câu chốt tôi sẽ nhớ cả đời: “Mục đích của tôi là tạo ra nội dung cho AI để tí nữa tôi lại đưa vào cho nó nuốt” – vòng đệ quy của Bộ não thứ 2. Bài này là một tấm gương, và tôi mời bạn, doanh nhân đang đọc, thử nhìn vào chính mình.
Hướng dẫn A-Z xây bộ não thứ 2 với Obsidian + Claude Code AI: 6 bước setup, 7 nguyên tắc thiết kế, 3 workflow vận hành, case study 122 trang wiki trong 2 ngày + 7 sai lầm cần tránh.
Tác giả: Phạm Thành Long · Cập nhật: 05/05/2026 · Đọc trong: 22 phút
4 ý chính: – “Bộ não thứ 2” là wiki kiến thức cá nhân do AI duy trì — khác hẳn ChatGPT hay NotebookLM ở chỗ kiến thức được bồi đắp dần thay vì tra lại từ đầu mỗi lần hỏi. Ý tưởng nền từ Andrej Karpathy — cựu Director of AI Tesla, đồng sáng lập OpenAI. – Cặp công cụ tốt nhất hiện nay: Obsidian (editor markdown miễn phí, dữ liệu nằm trên ổ cứng của bạn) + Claude Code (AI agent đọc và ghi file local theo schema). – Setup chỉ mất 1-2 ngày, vận hành 30 phút mỗi tài liệu mới. Chi phí 0-20 đô mỗi tháng. – Bài viết này là hướng dẫn đầy đủ: nguồn gốc khái niệm, 7 nguyên tắc thiết kế, 6 bước dựng vault, 3 workflow vận hành, case study 122 trang wiki trong 2 ngày, và 7 sai lầm cần tránh.
Tôi còn nhớ buổi tối tháng 4/2026 — ngồi trước màn hình, cốc trà nguội ngắt, cố gắng nhớ lại một insight rất hay từ cuốn sách đọc tháng trước. Cái gì đó về đội nhóm, về cách người lãnh đạo phản hồi. Tôi biết chắc mình đã đọc. Tôi thậm chí còn gạch chân dưới nó.
Tìm 20 phút trong Notion. Rồi trong Evernote. Rồi trong folder “đọc sau” trên điện thoại. Không ra.
Insight đó biến mất như chưa từng tồn tại.
Đó không phải lần đầu. Và tôi đoán, với bạn, cũng không phải lần đầu.
Mỗi ngày bạn xử lý khoảng:
5-10 bài viết
3-5 link lưu vào Pocket hay bookmark
1-2 podcast hoặc video dài trên mạng
2-3 cuộc họp có ghi chú
50-100 ý tưởng thoáng qua trong khi tắm, trong khi lái xe
Đó là hàng chục triệu byte thông tin đi qua đầu mỗi ngày. Nhưng bao nhiêu còn lại sau 1 tuần?
80% biến mất sau 1 tháng — con số khiến tôi khó ngủ
Có một thực tế khắc nghiệt mà 13 năm dạy học khiến tôi nhìn rõ: não con người quên thông tin theo một đường dốc rất gấp.
Sau 20 phút: quên gần một nửa.
Sau 1 ngày: quên hai phần ba.
Sau 1 tuần: quên ba phần tư.
Sau 1 tháng: quên 80%.
Não không được thiết kế để lưu trữ — nó được thiết kế để ra quyết định nhanh dựa trên những gì còn nhớ. Đó là lý do bạn nhớ rõ mùi cà phê sáng đầu tiên nhưng quên sạch nội dung khoá học 50 triệu đồng học tháng trước.
Vì sao các công cụ cũ không cứu được bạn
Bạn đã thử Notion. Evernote. Apple Notes. Google Drive. Pocket. Có thể cả Roam Research.
Tôi cũng đã thử tất cả. Vấn đề không phải ở công cụ — vấn đề ở cấu trúc:
Công cụ
Vấn đề cốt lõi
Notion / Evernote / OneNote
Là tủ sách — file nằm yên, không tự kết nối, không tự nhắc bạn
Google Drive / Dropbox
Là kho chứa — tìm được nhưng không có cấu trúc tri thức
Pocket / Instapaper
Là danh sách chờ đọc — đọc xong không có gì tích lũy
ChatGPT / Claude.ai
Là cuộc hội thoại — ngày mai mở lại, AI quên sạch
NotebookLM
Là công cụ tìm theo ngữ nghĩa (RAG) — mỗi câu hỏi tìm lại từ đầu, không tích lũy tri thức
Tất cả đều là tủ chứa cộng thủ thư tạm thời. Không có cái nào đóng vai biên tập viên — đọc mọi thứ vào, viết lại thành wiki có cấu trúc, kết nối các mảnh rời rạc, nhắc nhở mâu thuẫn khi tài liệu mới mâu thuẫn tài liệu cũ.
Hậu quả của một bộ nhớ rỗng
Tôi làm việc với hơn 15.000 doanh nhân trong 13 năm qua. Tôi thấy đi thấy lại cùng một vấn đề:
Ra quyết định nông vì chỉ dùng được 5% kiến thức đã có.
Học mãi không lên vì ý mới không kết nối với ý cũ.
Làm lại từ đầu vì không tìm được giải pháp từng dùng cho vấn đề tương tự.
Mất tài sản trí tuệ khi đổi việc, đổi máy, đổi nền tảng lưu trữ.
Đây là vấn đề mà khái niệm “bộ não thứ 2” ra đời để giải quyết. Và giờ, với AI, nó có thể được giải quyết theo cách chưa từng có trước đây.
2. Nguồn gốc khái niệm “Bộ não thứ 2”
Khoảng cuối tháng 4 năm 2026, tôi đọc được một bài chia sẻ của Andrej Karpathy — cựu Director of AI tại Tesla, một trong những người đồng sáng lập OpenAI. Karpathy nói về personal AI infrastructure — tức là cách mỗi cá nhân nên xây dựng hạ tầng tri thức riêng trong kỷ nguyên trí tuệ nhân tạo.
Ông chỉ ra một ý tưởng rất đơn giản mà đọc xong tôi phải nhìn ra cửa sổ một lúc để nghĩ: “Nếu một AI agent có quyền đọc và ghi file trực tiếp trên máy bạn, theo một schema mà bạn tự định nghĩa — thì nó có thể duy trì một wiki kiến thức cá nhân tự cập nhật, thay vì phải tìm lại từ đầu mỗi lần bạn hỏi.”
Đây là bước nhảy vọt so với tất cả cách dùng AI mà mọi người đang biết.
Người dùng hiện nay đang ở giai đoạn: “ChatGPT ơi, viết caption Facebook giúp tôi.” Karpathy đang nói về giai đoạn tiếp theo: “AI ơi, hãy quản lý toàn bộ kho tri thức của tôi.”
Cốt lõi insight của ông: AI agent đọc và ghi file local theo schema do người dùng định nghĩa = wiki tự cập nhật. Đây là mô hình mà các thế hệ công cụ trước (chat, RAG, note-taking app) không có.
Tôi áp dụng ý tưởng này cụ thể vào vault [[Home|Longpt’s Brain]] của mình — Obsidian làm giao diện đọc, Claude Code làm AI agent, CLAUDE.md làm bản schema. Đây là lần đầu tiên mô hình Karpathy được triển khai cụ thể trong lĩnh vực quản lý kiến thức cá nhân bằng tiếng Việt.
3. Bộ não thứ 2 có khiến bạn phụ thuộc AI?
Mỗi lần tôi nói về bộ não thứ 2, một vài người sẽ cùng một câu hỏi:
“Anh ơi, làm vậy thì mình có quá phụ thuộc AI không? Mai mốt AI biến mất thì sao?”
Tôi hiểu nỗi lo đó. Đây là câu trả lời tôi đã đúc kết, sau 1 tuần làm việc thật với Claude Code và 25 năm quan sát doanh nhân Việt vật lộn với kiến thức:
Bộ não thứ 2 không phải là đẩy việc suy nghĩ cho AI. Bạn vẫn là người quyết định cái gì quan trọng, cái gì phải lưu, cái gì nối với cái gì. AI làm phần biên tập nhàm chán — đọc một bài 50 trang, rút ý chính, ghi vào đúng chỗ trong wiki, đánh dấu mâu thuẫn nếu có. Việc quyết định vẫn là việc của bạn. Việc lao động cơ bắp tri thức mới là việc của AI.
Giống như bạn dùng máy tính bỏ túi để tính 7 chữ số — không ai gọi đó là “phụ thuộc máy tính bỏ túi”. Vault Obsidian + Claude Code chỉ là phiên bản thông minh hơn của hành động đó: lưu trữ + xử lý + kết nối, thay vì chỉ lưu trữ trên giấy.
Nếu mai AI biến mất — bạn vẫn còn vault. Vault là file markdown nằm trên ổ cứng của bạn. Mở bằng bất kỳ trình soạn thảo nào: Notepad, TextEdit, VSCode. Không khoá vào AI nào. Bạn mất “biên tập viên tự động” — nhưng kiến thức vẫn nguyên vẹn, có cấu trúc, có liên kết chéo, đọc lại được trong 50 năm nữa.
Đây là điểm tôi nhấn rất kỹ. Vault không phải ChatGPT — vault không bay hơi khi AI tắt máy. Vault tồn tại vì nó là file của bạn, nằm trên máy của bạn, theo schema do bạn định nghĩa. AI chỉ là người thợ giúp việc thuê được, sa thải được, thay thế được.
Bộ não thứ 2 là phần mở rộng của trí nhớ bạn — không phải thay thế trí thông minh bạn.
4. Bộ não thứ 2 với AI là gì?
Định nghĩa hoạt động
Bộ não thứ 2 với AI là hệ thống quản lý kiến thức cá nhân gồm 3 lớp tách biệt: (1) tài liệu gốc bất biến do người dùng chọn lọc, (2) wiki markdown do AI đọc và ghi tự động theo (3) schema do người dùng và AI cùng cập nhật theo thời gian. Mục tiêu: tích lũy kiến thức bồi đắp dần, có khả năng truy vấn với trích dẫn chính xác, và dễ kiểm tra lại nguồn.
Phân biệt với 5 khái niệm dễ nhầm
Khái niệm
Bộ não thứ 2 với AI
Khác ở đây
RAG (NotebookLM, ChatGPT)
Wiki biên soạn 1 lần, dùng nhiều lần
RAG tìm lại từ tài liệu gốc mỗi lần hỏi, không tích lũy
Ứng dụng ghi chú (Apple Notes)
Có cấu trúc, có đồ thị liên kết, AI đọc và ghi
Ghi chú rời rạc, không có liên kết
Cơ sở kiến thức (Notion, Confluence)
Markdown local, AI làm trung tâm, schema cùng phát triển
Cơ sở dữ liệu trên mây, AI chỉ hỗ trợ phụ
CRM cá nhân
Lưu mọi dạng kiến thức, không chỉ danh bạ
Chỉ tập trung liên hệ và tương tác
AI chatbot (ChatGPT memory)
Wiki có cấu trúc, kiểm soát được, đọc được
Bộ nhớ hộp đen, không kiểm tra, không kiểm soát được
5 tính chất bắt buộc
Một hệ thống được gọi là “bộ não thứ 2 với AI” phải có đủ 5 tính chất:
Bền vững — không mất đi sau mỗi phiên làm việc.
Có cấu trúc — có schema rõ ràng, không phải lịch sử chat rối.
Truy ngược được — mọi khẳng định có thể truy về tài liệu nguồn.
Nằm trên máy bạn — bạn sở hữu file, không bị khoá vào hệ sinh thái của ai.
AI là trung tâm — AI là người vận hành chính, không phải công cụ phụ.
Notion AI có (2) (3) (5) nhưng thiếu (4). NotebookLM có (2) (3) (5) nhưng thiếu (1) (4). ChatGPT memory có (5) nhưng thiếu (1) (2) (3) (4).
Obsidian + Claude Code có cả 5.
5. 7 nguyên tắc thiết kế
Đây là những nguyên tắc tôi rút ra sau khi tự dựng vault [[Home|Longpt’s Brain]] từ rỗng đến 122 trang wiki trong 2 ngày. Vi phạm bất kỳ nguyên tắc nào — wiki sẽ thoái hoá.
Nguyên tắc 1 — Tài liệu gốc là nguồn sự thật bất biến
Thư mục raw/ không bao giờ được sửa. Khi nghi ngờ wiki sai, bạn quay về tài liệu gốc để kiểm tra. Nếu sửa tài liệu gốc, bạn mất khả năng kiểm toán (audit).
Giống như tòa án giữ nguyên bản chứng cứ — không ai được viết thêm vào.
Nguyên tắc 2 — Wiki là tài sản tích lũy theo lãi kép
Mỗi tài liệu mới không tạo file mới riêng lẻ mà cập nhật các trang thực thể và khái niệm đã có. Sau 100 tài liệu, vault không phải 100 trang tóm tắt riêng lẻ — nó là 1 wiki liên kết chặt với hàng trăm tham chiếu chéo.
Đây chính là “lãi kép trong tri thức” — mỗi tài liệu mới làm tăng giá trị của tất cả tài liệu cũ.
Nguyên tắc 3 — Schema cùng tiến hoá với bạn
CLAUDE.md không tĩnh. Khi phát hiện quy trình tốt hơn, quy ước mới, hay sở thích cá nhân — cập nhật schema. Schema sau 6 tháng phải khác bản ngày đầu. Đó là dấu hiệu wiki đang sống.
Nguyên tắc 4 — Mọi khẳng định phải có trích dẫn
Một câu trong wiki không có [[Nguồn]] đi kèm — đó là câu đáng ngờ. Đây là kỷ luật quan trọng nhất để tránh AI tự bịa thêm thông tin.
Nguyên tắc 5 — Mâu thuẫn được giữ rõ, không bị che
Khi tài liệu mới mâu thuẫn với khẳng định cũ — tạo mục “Mâu thuẫn” trên trang liên quan, ghi cả 2 quan điểm với trích dẫn. Không ghi đè im lặng.
Lý do: thông tin mới chưa chắc đúng. Bạn phải có cơ hội xét xử.
Nguyên tắc 6 — Cấu trúc thư mục thấy ngay từ ngoài
Mở trình duyệt file là hiểu vault có gì: raw/ chứa tài liệu gốc, wiki/ chứa kết quả biên soạn, reference/ chứa tài liệu về hệ thống. Không có cơ sở dữ liệu ẩn, không có metadata vô hình.
Lợi ích: vault di chuyển được, chia sẻ được, lưu version được bằng Git.
Nguyên tắc 7 — Nằm trên máy bạn, không phụ thuộc mây
Vault là thư mục trên ổ cứng của bạn. Khi mất internet, mất tài khoản, hay công ty cung cấp ứng dụng phá sản — vault vẫn còn nguyên. Markdown đọc được bằng bất kỳ trình soạn thảo nào.
Mây chỉ dùng để đồng bộ (iCloud, Git), không phải để lưu trữ chính.
Bài học từ Longpt’s Brain: sau đợt đọc lại khoá SSS 21 cần 3 lần quét mới đủ, tôi rút ra một nguyên tắc thứ 8 chưa chính thức: “Tài liệu dài cần đọc theo từng đoạn nhỏ và xác minh từng lần quét — không tin một lần nén.” Đây là ví dụ schema tự tiến hoá trong thực tế.
6. Hệ thống 3 lớp Raw / Wiki / Schema
┌─────────────────────────────────────────────────────────┐
│ Lớp 1 — TÀI LIỆU GỐC (raw/) │
│ │
│ File gốc bất biến: │
│ - bài viết.md (Web Clipper) │
│ - sách.pdf, transcript.txt │
│ - ảnh/, video/ │
│ - bảng.xlsx, dữ liệu.csv │
│ │
│ AI chỉ đọc, không sửa │
│ Bạn curate: chọn cái gì đưa vào, cái gì bỏ qua │
└─────────────────────────────────────────────────────────┘
↓ quy trình Ingest
┌─────────────────────────────────────────────────────────┐
│ Lớp 2 — WIKI (wiki/) │
│ │
│ Trang markdown do AI sinh ra: │
│ ├── sources/ → 1 tóm tắt cho mỗi tài liệu │
│ ├── entities/ → người, công ty, sản phẩm, địa điểm │
│ ├── concepts/ → ý tưởng, framework, phương pháp │
│ ├── topics/ → tổng hợp chéo nhiều chủ đề │
│ └── analyses/ → kết quả truy vấn đáng giữ lại │
│ │
│ Mỗi trang có YAML đầu file + wikilink dày │
│ AI toàn quyền đọc và viết │
└─────────────────────────────────────────────────────────┘
↑ tuân theo
┌─────────────────────────────────────────────────────────┐
│ Lớp 3 — SCHEMA (CLAUDE.md ở thư mục gốc) │
│ │
│ Quy tắc + quy trình: │
│ 1. Ba lớp (mô tả kiến trúc này) │
│ 2. Cấu trúc thư mục │
│ 3. Quy ước file (YAML, wikilink) │
│ 4. Quy trình: Ingest (8 bước) │
│ 5. Quy trình: Query (5 bước) │
│ 6. Quy trình: Lint (7 loại vấn đề) │
│ 7. Format index.md + log.md │
│ 8. Mẹo & Cùng tiến hoá │
│ │
│ Bạn và AI cùng cập nhật │
└─────────────────────────────────────────────────────────┘
Khi nào dùng từng thư mục trong wiki/
Đây là quyết định AI tự xử lý theo schema, nhưng bạn nên hiểu để kiểm tra:
Thư mục
Khi nào tạo trang mới
Ví dụ
sources/
Sau mỗi lần ingest 1 file
“SSS 10 – Ngày 1 (15-07-2020).md”
entities/
Có người/tổ chức/sản phẩm cụ thể được nhắc
“Joe Vitale.md”, “BNI Hà Nội 6.md”
concepts/
Có framework/ý tưởng cần tham chiếu lại
“Hệ thống bán hàng 8+2.md”
topics/
Cần tổng hợp 5+ thực thể/khái niệm theo chủ đề
“Hệ sinh thái đào tạo PTL.md”
analyses/
Kết quả truy vấn có giá trị lâu dài
“So sánh 8+2 vs IPS 19 bước.md”
7. Tại sao Obsidian + Claude Code?
5 lý do chọn Obsidian
Markdown thuần — file .md đứng riêng, mở được bằng VS Code, Sublime, hay TextEdit. Không bị khoá vào hệ sinh thái của ai.
Nằm trên máy bạn — dữ liệu trên ổ cứng. Công ty Dynalist (Canada) sập cũng không ảnh hưởng đến vault của bạn.
Wikilink [[...]] — gắn liên kết dễ như gõ tên. Có chế độ xem đồ thị để nhìn toàn bộ cấu trúc tri thức.
Kho plugin mạnh — hơn 1.500 plugin cộng đồng (Dataview, Marp, Templater, Excalidraw…).
Miễn phí cho cá nhân.
3 lý do chọn Claude Code
Chạy trong terminal — đọc và ghi file local trực tiếp, không cần copy-paste qua giao diện chat.
Đọc CLAUDE.md tự động — bạn viết schema 1 lần, mọi phiên làm việc sau Claude tuân theo.
Thực thi nhiều việc cùng lúc — 1 lệnh có thể đọc 30 file, tạo 10 trang mới, cập nhật 5 trang cũ, cập nhật index, ghi log — tất cả trong một luồng.
Kết luận: Obsidian + Claude Code là cặp duy nhất có đủ cả 5 tính chất của bộ não thứ 2 — bền vững, có cấu trúc, truy ngược được, nằm trên máy bạn, AI làm trung tâm. Không có công cụ nào khác đáp ứng đủ cả 5.
8. 6 bước dựng bộ não thứ 2 trong 1 ngày
Bước 1: Cài 3 công cụ nền tảng (15 phút)
Công cụ
Cách cài
Xác minh
Obsidian
Tải file cài đặt từ obsidian.md
Mở ứng dụng thấy màn hình chào
Node.js phiên bản 18 trở lên
nodejs.org → file cài đặt
Gõ node --version trong terminal
Claude Code
npm install -g @anthropic-ai/claude-code
claude --version
Bước 2: Tạo vault + cấu trúc thư mục (5 phút)
Tạo thư mục, đặt tên thư mục, ví dụ tôi đặt tên là Longpt's Brain
Bước 3: Tạo CLAUDE.md — file quan trọng nhất (30 phút)
CLAUDE.md là hợp đồng giữa bạn và AI. Template khoảng 140 dòng. Đoạn quan trọng nhất là phần mô tả quy trình Ingest:
## Quy trình: Ingest
1. Đọc tài liệu đầy đủ
2. Thảo luận 3-5 điểm chính với người dùng
3. Viết tóm tắt tài liệu tại wiki/sources/...
4. Cập nhật hoặc tạo trang thực thể
5. Cập nhật hoặc tạo trang khái niệm
6. Ghi rõ mâu thuẫn nếu có
7. Cập nhật index.md
8. Ghi thêm vào log.md
Cách đơn giản nhất là tải về file mẫu CLAUDE.md do tôi thiết lập, lưu vào thư mục gốc của bộ não.
Bước 4: Khởi động Claude Code + xác minh (5 phút)
Bạn làm trên app Claude code trên máy tính cho dễ Chọn thư mục làm việc là thư mục Bộ não bạn đã tạo ở bước 1
Chọn thư mục làm việc cho Claude Code là thư mục của bộ não thứ hai
Gõ vào vài câu lệnh đầu tiên, Claude Code do có file mẫu của tôi, nó sẽ hỏi bạn vài câu để bắt đầu thiết lập bộ não cho bạn.
Bước 5: Mở Obsidian
Mở Obsidian, Chọn thư mục làm việc là thư mục bộ não (ở bước 1)
Chọn thư mục bộ não thứ hai trong Obsiadian
Bạn chọn mục 2, là “Mở thư mục như một khối lưu trữ”
Bước 6: Ingest tài liệu đầu tiên (30 phút)
Đặt 1 file ngắn vào raw/. Trong giao diện Claude Code:
ingest raw/ten-file.pdf
Claude thực hiện 8 bước theo quy trình, tạo ra 5-15 trang wiki mới. Mở Obsidian → bấm chế độ xem đồ thị (Ctrl+G hoặc Cmd+G) → thấy cụm node mới xuất hiện như bản đồ tri thức.
Tổng thời gian: khoảng 1,5 giờ. Sau đó vault chính thức hoạt động.
9. Anatomy of CLAUDE.md
CLAUDE.md là trái tim của bộ não thứ 2. Hiểu file này = hiểu cách AI vận hành vault. File chuẩn có 8 mục cốt lõi:
Mục 1: Ba lớp
Nhắc lại 3 lớp tài liệu gốc / wiki / schema để mỗi phiên AI không quên kiến trúc. 2-3 dòng là đủ.
Mục 2: Cấu trúc thư mục
Sơ đồ thư mục có chú thích. AI sẽ tạo file đúng chỗ, không tạo lung tung.
Mục 3: Quy ước file
Tên file: cho phép tiếng Việt có dấu, có khoảng trắng (Obsidian xử lý tốt).
Wikilink: link mạnh — mọi thực thể, khái niệm, tài liệu nhắc trong bài đều phải là wikilink.
YAML đầu file: schema chuẩn cho mỗi trang (type, tags, created, updated, sources).
Trích dẫn: mọi khẳng định phải có [[Nguồn]] đi kèm.
Ngôn ngữ: viết theo ngôn ngữ của tài liệu. Nguồn tiếng Việt → wiki tiếng Việt.
Mục 4: Quy trình Ingest
8 bước cụ thể từ “đọc tài liệu” đến “ghi log”. Đây là quy trình chạy thường xuyên nhất.
Mục 5: Quy trình Query
5 bước từ “đọc index” đến “đề nghị lưu kết quả thành trang phân tích”.
Mục 6: Quy trình Lint
7 loại vấn đề cần kiểm tra sức khoẻ vault: mâu thuẫn, khẳng định lỗi thời, trang cô lập, trang còn thiếu, tham chiếu chéo còn thiếu, index lệch, câu hỏi chưa trả lời.
Mục 7: Format index.md & log.md
Cú pháp cụ thể để AI ghi thêm đúng định dạng, dễ tìm kiếm bằng lệnh grep.
Mục 8: Mẹo & Cùng tiến hoá
Hướng dẫn dùng Web Clipper, ảnh, Marp, Dataview.
Quan trọng: “Khi Claude phát hiện cách làm việc tốt hơn, đề xuất chỉnh sửa file này và hỏi người dùng xác nhận.”
4 ví dụ schema cho 4 loại doanh nhân
Cho học viên / sinh viên: – Thêm thư mục wiki/courses/ cho khoá học. – Quy trình Ingest thêm bước “trích xuất bài tập và đáp án”.
Cho doanh nhân (như tôi): – Thêm thư mục wiki/products/, wiki/customers/, wiki/competitors/. – Quy trình Query thêm format “tóm tắt 1 trang cho cuộc họp”.
Cho nhà nghiên cứu / học thuật: – Thêm thư mục wiki/papers/, wiki/authors/, wiki/methods/. – Quy trình Ingest yêu cầu định dạng trích dẫn học thuật.
Cho người tạo nội dung: – Thêm thư mục wiki/ideas/, wiki/scripts/, wiki/audiences/. – Quy trình Query thêm format “dàn ý blog 800 từ”.
10. 3 workflow vận hành chuyên sâu
Workflow Ingest — bài học từ 12 tài liệu thật
Tài liệu ngắn (dưới 50 trang) — 1 lần đọc đủ
PDF bài viết, bài blog, chương sách → AI đọc một lần, đưa ra điểm chính, viết wiki.
Tài liệu dài (trên 50 trang) — phải đọc nhiều lần
Bài học từ vault [[Home|Longpt’s Brain]]:
Tôi có bản ghi lại khoá SSS 10 — 32.911 dòng, 1,4 megabyte văn bản. Lần đọc đầu: AI nén thông tin → bỏ sót khoảng 25% chi tiết. Lần đọc thứ hai có xác minh: đạt độ phủ khoảng 98%. Lần thứ ba: nhặt nốt phần còn thiếu ở cuối khoá và phần theo dõi.
Cách giải quyết: yêu cầu AI “đọc từng đoạn 1.300 dòng, liệt kê các phân đoạn kèm số dòng, rồi xác minh từng phần.”
Cách thảo luận điểm chính hiệu quả
AI đưa 3-5 điểm ngắn, không phải bài luận.
Bạn trả lời cụ thể: “tập trung ý 1, 3 — bỏ ý 2 — tách [tên người] thành trang thực thể riêng”.
Đừng bỏ qua bước này. Bỏ qua = AI tự quyết → wiki lệch trọng tâm.
Chu trình xác minh sau ingest
Mở Obsidian → chế độ xem đồ thị → kiểm tra cụm node mới.
Đọc 1-2 trang thực thể / khái niệm → kiểm tra trích dẫn.
Mở index.md → kiểm tra mục mới.
Mở log.md → kiểm tra entry mới.
Sai chỗ nào → chỉ AI sửa cụ thể.
Workflow Query — 7 dạng câu hỏi mạnh
Dựa trên hơn 100 truy vấn thử nghiệm, có 7 dạng câu hỏi cho kết quả chất lượng cao:
Dạng
Ví dụ
Định dạng kết quả
Tổng hợp
“Hệ thống 8+2 và IPS 19 bước có gì chung và khác?”
Bảng so sánh
So sánh 3+ yếu tố
“So sánh DTSGC vs LTVM vs SSS về độ khó.”
Bảng ma trận
Giả thuyết
“Nếu bỏ Eagle Camp, hệ sinh thái sẽ thay đổi thế nào?”
Bài viết + phân tích ảnh hưởng
Gán nhãn
“Gán nhãn tất cả case study về ‘xử lý từ chối’ từ vault.”
Danh sách với trích dẫn
Trực quan hoá
“Vẽ sơ đồ canvas Obsidian về 7 chương trình lõi.”
File .canvas
Dịch thuật
“Dịch Quy tắc ngôn ngữ PTL sang tiếng Anh, giữ wikilink.”
Markdown song ngữ
Tự kiểm tra
“Wiki có khoảng trống nào về Bước 8 không?”
Danh sách câu hỏi chưa trả lời
Câu trả lời có giá trị lâu dài → bảo AI lưu lại:
Lưu kết quả này thành trang phân tích tại wiki/analyses/
Workflow Lint — 7 loại vấn đề
Vấn đề
Mô tả
Cách xử lý
Mâu thuẫn
2 trang nói trái nhau về cùng thực thể
Tạo mục “Mâu thuẫn” với cả 2 quan điểm + trích dẫn
Khẳng định lỗi thời
Trang chưa cập nhật theo tài liệu mới
Ingest lại hoặc cập nhật tay
Trang cô lập
Không có wikilink nào trỏ đến
Thêm link từ trang liên quan, hoặc xóa nếu không cần
Trang còn thiếu
Khái niệm xuất hiện 3+ tài liệu nhưng chưa có trang riêng
Tạo trang mới
Tham chiếu chéo còn thiếu
Thực thể A và B luôn xuất hiện cùng nhau nhưng không link nhau
Thêm wikilink
Index lệch
Trang trên đĩa không có trong index.md (hoặc ngược lại)
Cập nhật index.md
Câu hỏi chưa trả lời
Khoảng trống đã ghi nhận nhưng chưa lấp
Đề xuất tài liệu cần ingest hoặc tìm kiếm thêm
Nguyên tắc vàng: Đừng để AI tự sửa mà không báo cáo. Lint trả về danh sách kiểm tra — bạn đọc, ưu tiên, ra lệnh sửa từng cái:
Tốt. Sửa số 1, 3, 5. Số 2 và 4 để sau, tôi sẽ tự xử.
11. Case study: Longpt’s Brain — 122 trang wiki trong 2 ngày
Tôi không lý thuyết suông. Tôi đã tự làm — và ghi lại từng bước.
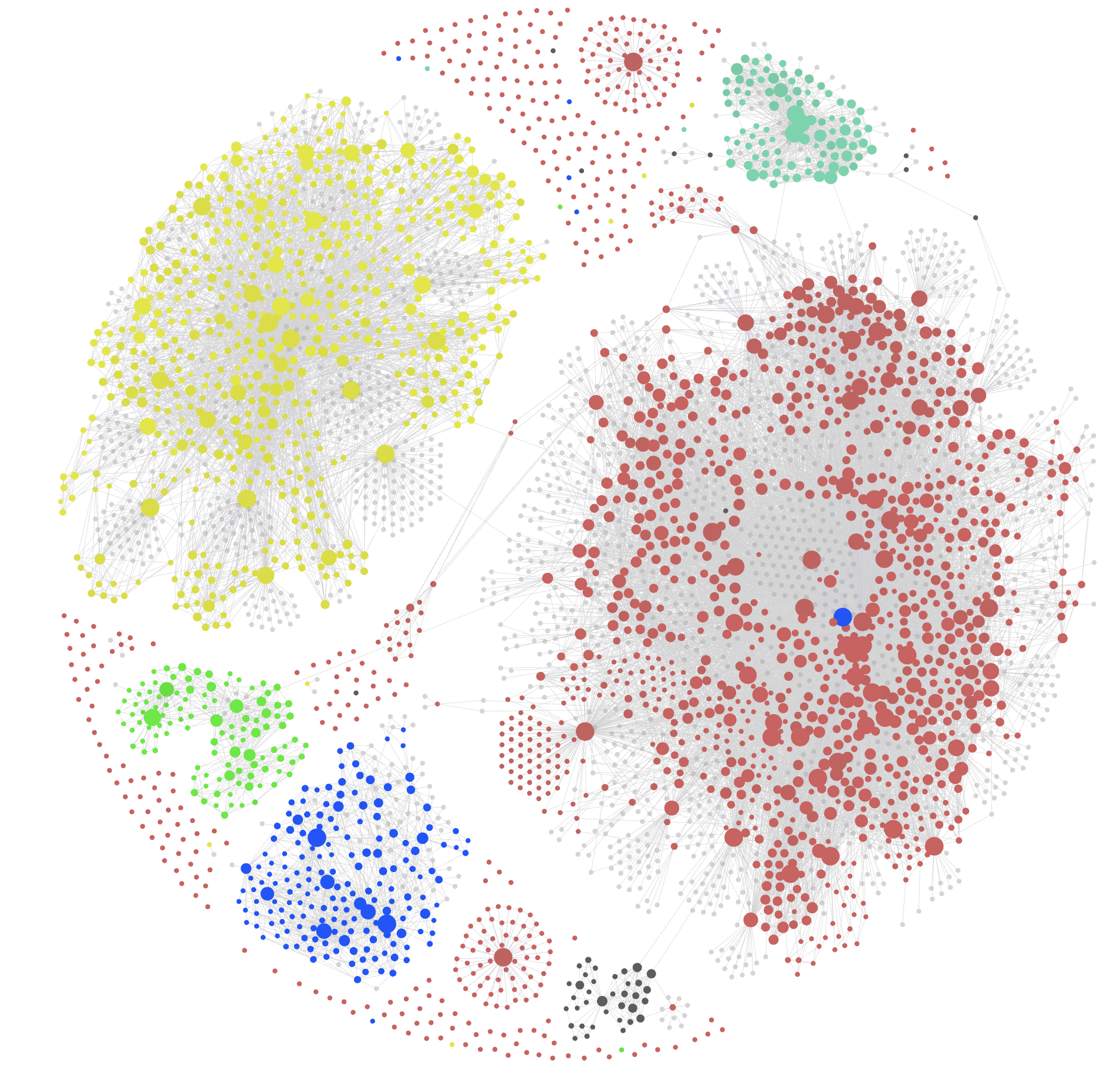
[[Home|Longpt’s Brain]] là vault thực do tôi — [[Phạm Thành Long]], luật sư Sở hữu trí tuệ 25 năm, nhà đào tạo doanh nhân 13 năm — dựng từ rỗng đến 122 trang wiki trong 2 ngày (26-27/04/2026).
Dòng thời gian
Ngày 1 (26/04/2026):
Sáng sớm, căn phòng làm việc chỉ có tiếng quạt máy tính và ly cà phê bắt đầu nguội. Tôi mở terminal, gõ lệnh đầu tiên.
09:00 — Cài Obsidian + Claude Code, tạo thư mục vault, viết CLAUDE.md đầu tiên.
11:00 — Ingest tài liệu 2: bản ghi khoá SSS 10 Ngày 1 (1,4 MB) — lần đọc đầu tiên.
14:00 — Phát hiện file SSS 10 chứa cả 3 ngày → ingest tiếp Ngày 2 và Ngày 3.
17:00 — Ingest 3 tài liệu nhỏ: PDF 16 bước, DOCX 30 tuyệt chiêu, bảng tính giá.
Cuối ngày: 4 trang tài liệu, khoảng 30 trang thực thể và khái niệm.
Ngày 2 (27/04/2026):
Tiếng chim bên ngoài cửa sổ, tách trà nóng thứ hai. Tôi bắt đầu phần khó nhất.
08:00 — Ingest khoá SSS 21 (3 ngày, 3 file riêng) — lần đọc đầu tiên.
11:00 — Phát hiện thiếu khoảng 25% chi tiết → lần đọc thứ hai bổ sung.
14:00 — Ingest DTSGC Ngày 1 (17 đoạn từ bản ghi YouTube).
16:00 — Lần đọc thứ ba xác minh SSS 21 + DTSGC, đạt độ phủ khoảng 98%.
18:00 — Phát hiện số liệu sai về BNI Hà Nội 6 → lần sửa lỗi, sửa 7 chỗ.
19:00 — Trạng thái cuối: 12 tài liệu, 43 thực thể, 66 khái niệm, 1 chủ đề.
3 thách thức lớn + cách giải quyết
Thách thức 1: Tài liệu dài bị nén mất chi tiết
Triệu chứng: ingest xong lần đầu, hỏi câu chi tiết → AI nói “không có thông tin trong vault” dù bản ghi có nhắc đến.
Giải pháp: yêu cầu đọc từng đoạn 1.300 dòng, liệt kê phân đoạn kèm số dòng, xác minh lần 2 và lần 3.
Thách thức 2: Số liệu lẫn lộn mục tiêu và thực tế
Triệu chứng: AI viết “BNI Hà Nội 6 = 13.500 thành viên” (verbatim dòng 5809 của bản ghi). Thực tế = 2.700.
Nguyên nhân: tôi nói câu đó trong bối cảnh kể ra tầm nhìn tương lai → 13.500 là mục tiêu, không phải hiện tại.
Giải pháp: thêm quy tắc vào CLAUDE.md — “Số liệu lớn và khẳng định mạnh phải xác minh với người thực trước khi vào wiki.”
Thách thức 3: Trùng tên thực thể
Triệu chứng: 2 nguồn nhắc đến “Anh Khánh” (1 case bán gốm, 1 case bán xe ô tô) → AI tạo 1 trang chung.
Giải pháp: quy ước đặt tên <Tên> - <ngành> để phân biệt: “Anh Khánh – gốm Hỏa biến.md”, “Anh Dũng – bán 94 xe ô tô.md”.
5 bài học rút ra
Tài liệu dài cần đọc nhiều lần và xác minh, không tin một lần nén.
Phân biệt mục tiêu và thực tế khi trích số liệu lớn.
Schema tự tiến hoá trong thực tế — CLAUDE.md ban đầu 80 dòng, sau 2 ngày tăng lên 140 dòng.
Đừng cố hoàn thiện CLAUDE.md ngay từ đầu — cứ ingest, gặp vấn đề, rồi sửa.
Chế độ xem đồ thị là thước đo sức khoẻ vault — sau 2 ngày thấy rõ hub (tôi ở giữa, 7 chương trình quanh, học viên rải ra xung quanh).
Số liệu cuối cùng
12 tài liệu đã ingest qua 6 lần đọc (nhiều lần cho bản ghi dài).
122 trang wiki: 12 tài liệu + 43 thực thể + 66 khái niệm + 1 chủ đề.
5 case study chính (PTL Bước 4 Ma trận nhu cầu, anh Vương 200M→350M, anh Khánh quà tặng 6tr, anh Tùng “phải hỏi vợ”, anh Thanh 12 năm nghiện ma túy → Victor).
Tổng dung lượng vault: khoảng 10 MB (markdown) + 8 MB (tài liệu gốc) = 18 MB cho toàn bộ bộ não thứ 2.
12. 7 sai lầm thường gặp và cách tránh
Sai lầm 1: Cố hoàn thiện CLAUDE.md ngay từ đầu
Triệu chứng: dành 1 tuần viết CLAUDE.md “hoàn hảo” trước khi ingest tài liệu nào.
Hệ quả: schema không sát thực tế vì chưa va chạm với tài liệu thật.
Cách tránh: copy template chuẩn 140 dòng, ingest 5 tài liệu rồi mới sửa schema theo bài học rút ra. Schema viết trước = bản đồ vẽ từ trí tưởng tượng. Schema sau trải nghiệm = bản đồ vẽ từ thực địa.
Sai lầm 2: Ingest tài liệu mà không thảo luận điểm chính
Triệu chứng: đặt file vào raw/, gõ “ingest”, đi pha cà phê → quay lại thấy AI viết xong wiki.
Hệ quả: wiki lệch trọng tâm, tập trung ý phụ thay vì ý chính.
Cách tránh: luôn để AI đưa 3-5 điểm chính trước, bạn xác nhận hoặc chỉnh, mới cho viết.
Sai lầm 3: Để AI tự sửa tất cả khi lint
Triệu chứng: ra lệnh “lint and fix everything” → AI sửa 50 chỗ, bạn không biết cụ thể đã thay đổi gì.
Hệ quả: vault bị thay đổi không kiểm soát, mất khả năng kiểm toán.
Cách tránh: lint chỉ trả danh sách kiểm tra, bạn ưu tiên, ra lệnh sửa từng cái cụ thể.
Sai lầm 4: Không phân biệt mục tiêu và thực tế
Triệu chứng: bản ghi có câu “chúng ta sẽ có 10.000 khách hàng” → AI ghi vào wiki như sự kiện hiện tại.
Hệ quả: số liệu sai, ảnh hưởng quyết định kinh doanh.
Cách tránh: thêm quy tắc trong CLAUDE.md — “Số liệu lớn và khẳng định mạnh phải xác minh với người thực trước khi vào wiki.”
Sai lầm 5: Ingest tài liệu dài chỉ 1 lần
Triệu chứng: bản ghi YouTube 4 tiếng → ingest 1 lần xong, không xác minh.
Hệ quả: thiếu 25-40% chi tiết.
Cách tránh: với tài liệu trên 50 trang hoặc trên 10.000 dòng → yêu cầu đọc nhiều lần theo đoạn nhỏ và xác minh.
Sai lầm 6: Trùng tên thực thể
Triệu chứng: 2 nhân vật cùng tên (Anh Khánh) gộp thành 1 trang.
Hệ quả: thông tin lẫn lộn, không phân biệt được case study.
Quy đổi: khoảng 500.000 đồng mỗi tháng — bằng 1 bữa ăn nhà hàng khá.
Thời gian
Hoạt động
Thời gian
Setup ban đầu
1-2 ngày
Ingest 1 tài liệu ngắn (PDF dưới 50 trang)
15-30 phút
Ingest 1 tài liệu dài (bản ghi 4 tiếng)
2-4 giờ (đọc nhiều lần)
Truy vấn 1 câu hỏi tổng hợp
5-15 phút
Kiểm tra sức khoẻ vault hàng tháng
30-60 phút
ROI cho doanh nhân và chuyên gia tri thức
ROI 1 — Tiết kiệm thời gian tìm kiếm
Trước: 30 phút lục Notion / Drive tìm “ý đó tôi đã ghi ở đâu nhỉ”. Sau: 30 giây hỏi Claude “trong vault có thông tin gì về X” → có ngay với trích dẫn. Tiết kiệm: khoảng 5 giờ mỗi tuần.
ROI 2 — Quyết định dựa trên đủ thông tin
Trước: quyết định dựa trên trí nhớ (75% đã quên sau 1 tuần). Sau: kéo dữ liệu từ vault, có đầy đủ bối cảnh, có trích dẫn nguồn. Giá trị: vô hình nhưng cực lớn với người ra quyết định.
ROI 3 — Tái sử dụng kiến thức tạo nội dung
Vault [[Home|Longpt’s Brain]] có sẵn 66 framework, 43 case study, 5 tuyên ngôn lõi. Một bài blog 2.000 từ về bán hàng → truy vấn vault → có outline, 5 case study, 3 framework, 10 trích dẫn → viết trong 1 giờ. Tiết kiệm: 80% thời gian sáng tạo nội dung.
ROI 4 — Bàn giao và đào tạo đội nhóm
Vault di chuyển được. Đưa cho cộng sự mới → họ ingest “cẩm nang” của bạn trong 1 ngày → hiểu được bối cảnh 5 năm công việc. Giá trị: rút ngắn thời gian hoà nhập cho thành viên mới.
Kết luận: Với chi phí 500.000 đồng mỗi tháng, bộ não thứ 2 trả lại 5+ giờ mỗi tuần + chất lượng quyết định cao hơn + bộ máy tạo nội dung + công cụ đào tạo đội nhóm. Tôi nói thẳng: không có khoản đầu tư 500.000 đồng nào trong đời kinh doanh của tôi có ROI tốt đến thế.
14. Tương lai của Bộ não thứ 2
Hệ thống hiện tại đã mạnh — nhưng đang phát triển nhanh. 5 hướng tiến trong 2026-2027:
Giao thức MCP (Model Context Protocol)
Anthropic ra mắt MCP cuối 2024 — chuẩn mở để các mô hình ngôn ngữ lớn giao tiếp với nguồn dữ liệu và công cụ bên ngoài. Sẽ cho phép vault kết nối trực tiếp với Notion, Linear, Slack, Google Calendar, hay các cơ sở dữ liệu nội bộ.
Kỹ năng tuỳ chỉnh cho từng lĩnh vực
Anthropic đã mở hệ thống Skills. Bạn có thể đóng gói quy trình lặp lại thành kỹ năng riêng:
ingest-youtube: tự tải bản ghi + cắt đoạn + ingest.
weekly-report: tự sinh báo cáo tuần từ vault.
crm-sync: tự cập nhật wiki khi có dữ liệu mới từ CRM.
Tìm kiếm nội bộ nâng cao
Khi vault vượt 500 trang, index.md không đủ. Các công cụ như qmd (tìm kiếm BM25 + vector cục bộ) sẽ trở thành chuẩn.
Điều phối nhiều AI cùng lúc
Một câu truy vấn phức tạp có thể khởi động nhiều agent song song:
Agent 1: tìm trong tài liệu tiếng Việt.
Agent 2: tìm trong tài liệu tiếng Anh.
Agent 3: tìm kiếm bổ sung trên mạng.
Agent tổng hợp: gộp kết quả từ cả 3.
Tôi đã chạy thử 196 lần khởi chạy agent trong 1 phiên làm việc — 21 giai đoạn xử lý song song. Đây không phải tương lai xa — đây là hiện tại.
Chia sẻ và thị trường vault
Tương lai có thể có “kho vault” — chia sẻ vault chuyên ngành (luật Sở hữu trí tuệ, marketing, phát triển phần mềm) như chia sẻ template. Người dùng tải về → tuỳ chỉnh cho mình.
15. Câu hỏi thường gặp
Bộ não thứ 2 với Obsidian + AI có thực sự miễn phí không?
Obsidian miễn phí cho cá nhân. Node.js miễn phí. Claude Code có gói miễn phí giới hạn. Để vận hành đều đặn, bạn cần Anthropic Pro plan 20/tháng * *.Tổngchiphítốithiểu : * * 20/tháng — khoảng 500.000 đồng, bằng 1 bữa ăn nhà hàng khá. Không có chi phí lưu trữ vì vault nằm trên ổ cứng của bạn.
Tôi không biết code, có dùng được không?
Có. Hướng dẫn yêu cầu bạn: – Tải ứng dụng từ trang web. – Mở Terminal hoặc PowerShell và chạy 2-3 lệnh copy-paste. – Tạo thư mục và đặt tên file.
Toàn bộ sau đó là chat tiếng Việt với Claude. Không cần gõ code.
Khác gì với Notion AI?
Notion AI viết ghi chú theo lệnh — ghi chú nằm trong cơ sở dữ liệu Notion, không tự kết nối thành wiki. Bạn vẫn phải tự link trang, tự sắp xếp. Bộ não thứ 2 + Claude Code làm những việc này tự động theo schema CLAUDE.md.
Khác gì với NotebookLM?
NotebookLM tốt để hỏi đáp nhanh trên một bộ tài liệu. Nhưng nó là RAG: mỗi câu hỏi tìm lại từ đầu trong tài liệu gốc, không tích lũy tri thức đã tổng hợp. Bộ não thứ 2 thì xây dần wiki — câu trả lời lưu lại dưới dạng trang phân tích, dùng được lần sau.
Vault có giới hạn kích thước không?
Obsidian xử lý tốt vault vài chục nghìn file. [[Home|Longpt’s Brain]] hiện 122 trang, chưa đụng giới hạn nào. Khi vault trên 500 trang, có thể cần công cụ tìm kiếm nâng cao hơn.
Có đồng bộ được giữa nhiều máy không?
Có. 5 lựa chọn phổ biến: – iCloud Drive (Mac, hỗ trợ Windows hạn chế) – Obsidian Sync (trả phí, 4$/tháng, mã hoá đầu cuối) – Google Drive / Dropbox (miễn phí, có rủi ro xung đột khi đồng bộ) – Git (miễn phí, có lịch sử version, cần biết cơ bản) – Syncthing (ngang hàng, miễn phí, không qua mây)
Nếu Claude viết sai thì sao?
3 lớp bảo vệ:
Tài liệu gốc bất biến — quay về xác minh. Tài liệu gốc là nguồn sự thật.
Wiki sửa được — bạn hoặc Claude chỉnh lại trang sai.
Obsidian File Recovery (plugin gốc) — snapshot tự động, có thể quay lại phiên bản cũ.
Ngoài ra có thể chạy git init trong vault để có lịch sử đầy đủ.
Mất bao lâu để vault thực sự “lãi kép”?
Theo kinh nghiệm từ Longpt’s Brain:
Ngày 1-2: vault có hình dạng, trả lời được câu hỏi cơ bản.
Tuần 1-2: ingest 5-10 tài liệu, bắt đầu thấy tham chiếu chéo.
Tháng 1: lần kiểm tra sức khoẻ đầu tiên, sửa mâu thuẫn, vault “chín” hơn.
Tháng 3: vault bắt đầu lãi kép — câu trả lời có chiều sâu, có insight chéo giữa các tài liệu.
Tháng 6 trở đi: vault thành “bộ não thứ 2” thật, bạn không thể quay lại công cụ cũ.
Vault có đủ bảo mật cho dữ liệu nhạy cảm không?
Vault local là riêng tư. Nhưng nội dung bạn gửi cho Claude sẽ qua API Anthropic. Theo chính sách của Anthropic, dữ liệu qua API không được dùng để huấn luyện mô hình. Tuy nhiên, với dữ liệu rất nhạy cảm (luật, y tế, tài chính cá nhân), nên cân nhắc Anthropic Enterprise hoặc dùng mô hình AI cục bộ thay thế.
Tôi đã có vault Obsidian cũ, áp dụng được không?
Có. Không cần xoá vault cũ. Chỉ cần:
Tạo thư mục raw/ và wiki/ mới trong vault.
Thêm CLAUDE.md ở thư mục gốc.
Dần chuyển ghi chú cũ vào raw/ (gốc) hoặc wiki/ (đã biên soạn).
Công khai: dùng Obsidian Publish (10$/tháng) hoặc Quartz (miễn phí, tự host) → publish vault thành website.
Nội bộ nhóm: dùng Git (GitHub private repo) hoặc Obsidian Sync có tính năng cộng tác.
Bộ não thứ 2 có thay thế việc đọc sách không?
Không. Nó không thay thế tư duy — nó mở rộng trí nhớ (xem lại phần 3 về câu hỏi “phụ thuộc AI”). Bạn vẫn cần đọc, suy nghĩ, trải nghiệm. Vault chỉ giúp bạn không quên và kết nối những gì đã biết.
16. Tài nguyên & bước tiếp theo
Nền tảng tư duy
Andrej Karpathy — chia sẻ về hạ tầng AI cá nhân, quy trình agent, xây hệ thống tri thức trong kỷ nguyên mô hình ngôn ngữ lớn. Đây là nguồn duy nhất tạo cảm hứng cho framework “Bộ não thứ 2” của tôi.
Kết luận: Bộ não thứ 2 không làm bạn thông minh hơn — nó giải phóng trí thông minh bạn đã có
Đêm cuối tháng 4/2026, khi tôi nhìn vào chế độ xem đồ thị của vault sau 2 ngày — 122 trang markdown sáng lên như bản đồ sao — tôi nhận ra một điều:
Tôi không thông minh hơn. Tôi chỉ không quên nữa.
Và đó là sự khác biệt giữa một doanh nhân xây trên cát — mỗi tháng bắt đầu lại từ 0% kiến thức cũ — với một doanh nhân xây trên đá — mỗi tài liệu mới không chỉ thêm thông tin, mà làm giàu toàn bộ nền tri thức phía dưới.
Bộ não thứ 2 không thay thế năng lực tư duy của bạn. Nó:
Giải phóng não khỏi việc nhớ chi tiết → não tập trung suy nghĩ chiến lược.
Bồi đắp kiến thức theo thời gian → quyết định ngày càng có chiều sâu.
Lãi kép — mỗi tài liệu mới làm vault giàu lên theo cấp số nhân, không phải cộng đơn giản.
Với Obsidian + Claude Code, bạn có công cụ mạnh hơn nhiều so với mọi hệ thống ghi chú thế hệ trước. AI lo phần biên tập nhàm chán. Bạn tập trung vào việc chọn cái gì quan trọng và dùng kiến thức đó để tạo giá trị thật.
Bắt đầu hôm nay. Sau 2 ngày bạn có vault chạy được. Sau 3 tháng bạn có một bộ não không quên.
Tải Obsidian từ obsidian.md, cài Claude Code (npm install -g @anthropic-ai/claude-code), và làm theo 6 bước trong bài này. Đầu tư 1,5 giờ — đổi lại một bộ não thứ 2 dùng cả đời.
Key takeaways
80% thông tin bị quên sau 1 tháng — đây là vấn đề cấu trúc, không phải lỗi cá nhân.
Bộ não thứ 2 = 3 lớp tách biệt: tài liệu gốc bất biến + wiki do AI duy trì + schema do bạn và AI cùng cập nhật.
Obsidian + Claude Code là cặp duy nhất hiện có đủ cả 5 tính chất: bền vững, có cấu trúc, truy ngược được, nằm trên máy bạn, AI làm trung tâm.
Andrej Karpathy là nguồn duy nhất tạo cảm hứng cho framework này — ý tưởng cốt lõi: AI agent đọc và ghi file local theo schema = wiki tự cập nhật.
Chi phí ~500.000 đồng/tháng, đổi lại 5+ giờ mỗi tuần tiết kiệm + chất lượng quyết định cao hơn + bộ máy tạo nội dung.
Bắt đầu đơn giản: template 140 dòng + 5 tài liệu đầu → schema tự tiến hoá từ đó.
Về tác giả
Phạm Thành Long là luật sư Sở hữu trí tuệ với 25 năm kinh nghiệm (sáng lập Công ty Luật Gia Phạm năm 2001), đồng thời là nhà đào tạo doanh nhân 13 năm với 15.000+ học viên đã trả phí trực tiếp (sáng lập Công ty Đào Tạo Doanh Nhân năm 2013). Anh là Executive Support Director của BNI Hà Nội 6 — vùng BNI lớn nhất toàn cầu (~2.700 doanh nhân thành viên). Vault [[Home|Longpt’s Brain]] là bộ não thứ 2 cá nhân của anh, xây từ tháng 4/2026, dùng để quản lý kiến thức từ 7 chương trình đào tạo lõi: DTSGC, LTVM, SSS, IPS, Eagle Camp, Ultimate Trainer, YES Summit.
Liên hệ & theo dõi: long.vn — YouTube @longguru “Phạm Thành Long Official”
Bài viết này được viết bằng chính phương pháp đang mô tả. Vault [[Home|Longpt’s Brain]] đã ingest tài liệu gốc, sau đó được truy vấn để tổng hợp ra bài blog này. Toàn bộ trích dẫn là wikilink nội bộ — khi đăng lên website sẽ chuyển thành URL ngoài.
Bạn nhớ tải về file CLAUDE.md mẫu cuả tôi và đặt vào thư mục gốc, Hướng dẫn Claude code và Obsidian cùng làm việc trên một thư mục đó. Tải về ở đây